Terraforming repeatable and extensible infrastructure
From where we started, Gojek has grown to be a community of more than one million drivers with three million+ orders every day in almost no time. To keep supporting this growth, hundreds of microservices run and communicate across multiple data centers to serve the best experience to our customers.
In this post, we’ll talk about our approach of assembling infrastructure as code that simplifies the maintenance of an increasingly complex microservices architecture for our company.
Motivation
Building infrastructure is, without a doubt, a complex problem evolving over time. Maintainability, scalability, observability, fault-tolerance, and performance are some of the aspects around it that demand improvements over and over again.
One of the reasons it is so complex is the need for high availability. Most of the components are deployed as a cluster with hundreds of microservices and thousands of machines. This constantly growing infrastructure took us to a place where no one knew what the managed infrastructure looked like, how the running machines were configured, what changes were made, and how networks were connected. In a nutshell, we lacked observability in our infrastructure, and when there was a failure in the system, it was hard to tell what could’ve brought the system down. Some of the unique challenges we encountered:
Infrastructure Expansion
With 4 countries, 20+ products, and 3 super apps, infrastructure keeps on expanding and there is always a requirement of launching data infrastructure for an entire product from the ground up.
Distributed teams
Multiple functions and teams spread across various locations and time zones have complex on-demand needs from the data infrastructure team.
Auto scaling
Higher elasticity of infrastructure, where instead of months or years, infrastructure might live for just a few hours traditional ticket-based on-demand setup for spinning up infrastructure is no longer practical.
Objectives
We have been using Terraform for our IAC(Infrastructure As Code) in bits and pieces for a while now, but it lacked structure and consistency. Different teams had different repositories. Modules were all over the place or inside the project itself. They were complex, and there were lots of bash scripts.
It was very challenging and error-prone to create infrastructure and maintain it manually. We needed to switch from updating our infrastructure manually and embracing end-to-end infrastructure as code.
IAC allows you to take advantage of all software development best practices. As a result, you can safely and predictably create, change, and improve infrastructure. Every network, server, database, every open network port can be written in code, committed to version control, peer-reviewed, and then updated as often as necessary.
Project Olympus is the Gojek infrastructure engineering team initiative to solve these problems and achieve the mentioned goals.
Declarative style infrastructure
Engineers write code that specifies its desired end state, and the IAC tool itself is responsible for figuring out how to achieve that state. With a declarative style, the code always represents the latest state of your infrastructure. Thus, at a glance, you can tell what’s currently deployed and configured without worrying about the past state.
Structure and consistency
Consistent workflow and code structure for developers to provision resources on any provider; central module registry to publish and discover modules that can be reused to provision the infrastructure of their choice.
Self-serve and On-demand infrastructure
A self-service model that allows engineers to pick the infrastructure best suited to run their workloads and provision it on-demand in a predictable and consistent way.
Safety and security
Provide fine-grained control on infrastructure operations for security, and safety and reduces human errors. All operations are limited to authorized users following data governance guidelines.
Accountability
With many moving pieces and large-scale infrastructure comes a vital need of allowing both ops teams and service owners to maintain observability of running applications and critical infrastructure.
Architecture
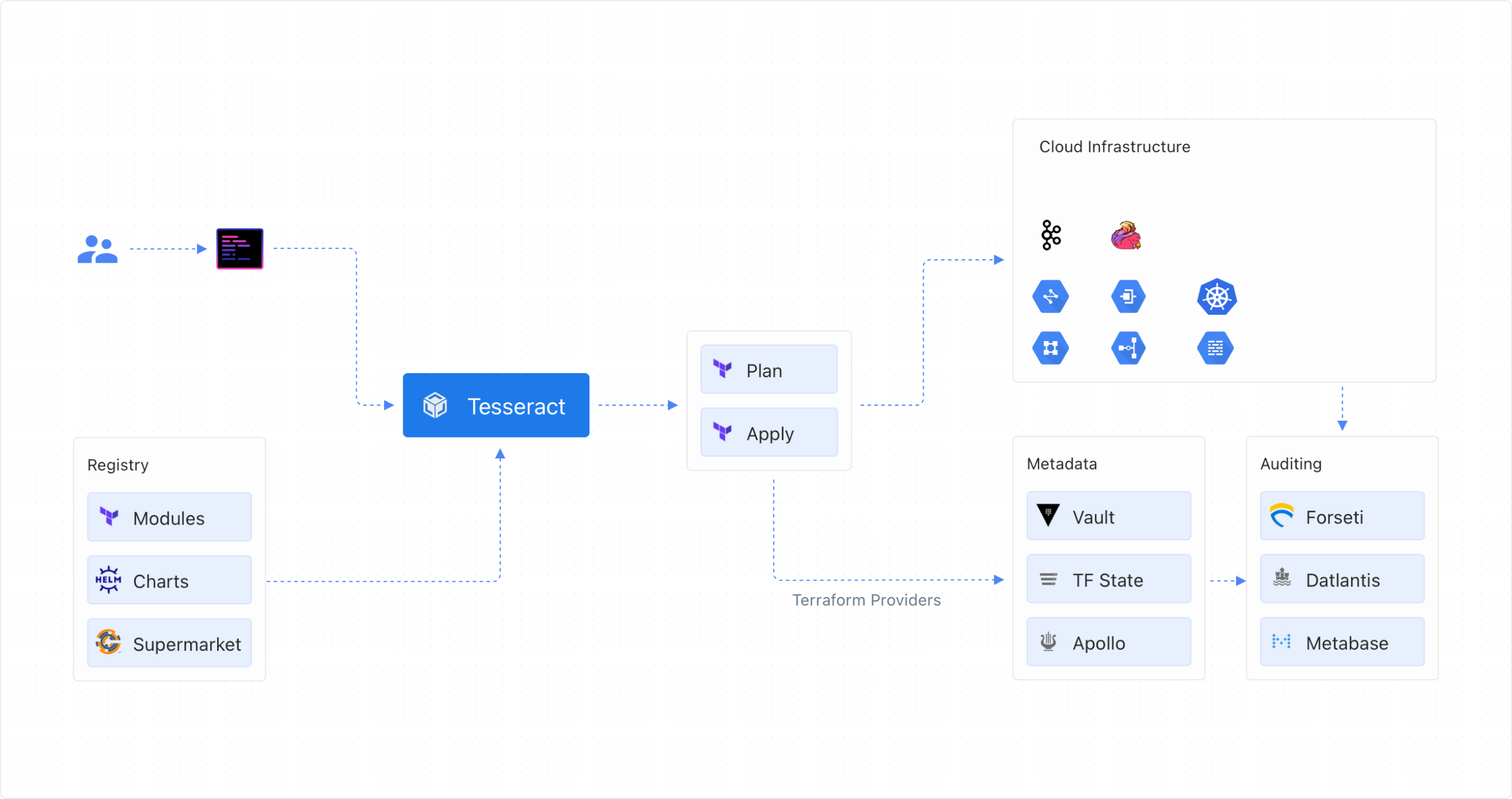
Module Registry
Modules in Terraform are self-contained packages of Terraform configurations used to create reusable components. Currently, we have more than 30 core base modules and a few abstracted modules built using composition on top of base modules.
module "kafka" {
source = "<path>/terraform/gcloud-kafka?ref=v1.0.1"
}
module "flink" {
source = "<path>/terraform/gcloud-kubernetes-flink?ref=v1.1.1"
cluster_name = "${var.cluster_name}"
teams = "${var.teams}"
}
module "kubernetes" {
source = "<path>/terraform/gcloud-kubernetes?ref=v1.0"
project_name = "${var.project_name}"
cluster_name = "${var.cluster_name}"
nginx_ingress_ip = "${module.kubernetes_base.nginx_ingress_ip}"
}
Terraform allows you to load private modules directly from git version control. The URLs for Git repositories support the ref query parameters. Terraform can use that to check out any branch, tag, or commit. Using ref, it becomes effortless to lock the version of modules in your IAC project.
module "godata_core_vpc" {
source = "<path>/terraform/gcloud-vpc.git?ref=v2.0.0"
project_name = "${var.project_name}"
vpc_name = "${var.landscape_name}"
subnet_region = "${var.subnet_region}"
gana_endpoint = "${var.gana_endpoint}"
}
We host our modules on the self-hosted Gitlab group, which is a central hub for all Terraform modules. The Infrastructure Engineering team maintains all base modules. Having a central module registry also allows us to enforce governance, compliance, and security against the modules made available to teams.
Infrastructure provisioner
The provisioner provides scaffolding as a foundation to jump-start your development. Users can run commands to scaffold entire projects or valuable parts. We use Proctor, an internal tool as our IAC scaffold tool.
Usage:
proctor provision [command]
Available Commands:
app-kminion Generate terraform code for deploying kminion for application side kafka
governance Generate terraform modules for governance
kube-foundation Generate terraform code for kube foundation
kubernetes Generate terraform modules for kubernetes
mirrormaker Generate mirrormaker from entity's landscape VPC to given destination project
network Generate terraform modules for network
ocean-governance Generate terraform modules for Ocean governance resources
project Generate terraform modules for project
radar-router Generate terraform code for Radar Router
stream Generate stream from entity's landscape VPC to given destination project
tunnel Generate tunnel from entity's landscape VPC to given destination project
Flags:
-h, --help help for provision
Global Flags:
--output-dir string Required, specify terraform root folder path
--template-dir string Required, specify template folder path
Use "proctor provision [command] --help" for more information about a command.
Network allocation
We have an internal tool called GANA- Gojek Assigned Numbers Authority that is responsible for coordinating the address allocation to resources like VPC, gateways, clusters, etc. It is an internal HTTP service with a custom-written terraform provider.
GANA provides a Terraform resource gana_allocate_subnet to allow allocating a subnet range for any resource type.
// Allocate a subnet to the resource
resource "gana_allocate_subnet" "subnet_allocate" {
project = "${var.project_name}"
category = "vpc"
network_name = "${var.subnet_name}"
endpoint = "${var.gana_endpoint}"
}
GANA also provides a Terraform data object for other projects to access subnet ranges of already allocated resources.
// Fetch details of the cluster subnet
data "gana_subnet" "godata_core" {
project = "${var.project_name}"
category = "vpc"
network_name = "godata-core"
endpoint = "${var.gana_endpoint}"
}
GANA allows us to
- Prevent IP ranges from clashing across different data centers and cloud projects.
- Provides a central place for accessing allocated resource information for use across different projects.
Metadata provider
We also have custom Terraform provider to capture metadata and push to a central metadata repository. Metadata is later used for referncing machine addressess, service discovery and more.
provider "godata" {
host = "http://xyz.gojek.io"
}
resource "godata_stream" "gmainstream" {
urn = "urn"
name = "mainstream"
brokers {
address = "10.11.12.10"
name = "g-godata-box-01"
host = "g-godata-box-01"
}
}
Code structure
Structuring the code in Terraform is crucial because it determines which files Terraform has access to when it is executing.
Olympus represents the entire Gojek live cloud infrastructure as IAC. Therefore, each repository in the its GitLab group represents one cloud project owned by their respective teams.
Having each project as a separate repository allows us to version control each project infrastructure separately. It also enables us to version physical infrastructure. The following example goviet-staging -1.2.3 maps to systems-1.2.3.
Infrastructure mapping enables us to roll back to older versions and always have working state mapping of the last stable infrastructure. The code structure within each project is layered where each layer represents one section of infrastructure and is a combination of similar components.
Lessons
Taking this project live gave us some important lessons about using Terraform at scale. Some of them are listed below:
Control blast radius
Terraform can “feel scary” since it’s easy to destroy infrastructure with only one command, making state management very important. One fundamental rule is to use remote state/remote backends. Terraform stores the state of the infrastructure in a JSON File. It is recommended to store that file on an external backend like Amazon S3 or Google cloud storage bucket.
We utilize our Terraform code structure to control the blast radius for our IAC state. To limit the scope of terraform destroy, our approach breaks down the state into “smaller” components, such as using different states for different projects, environments, and components.
Avoid module nesting
Maintaining versions of Terraform code can become cumbersome if modules have deep nesting. A small chnage in one module can trigger a huge chain of dependency upgrades to all your modules. We advise to keep your module nesting minimum to avoid versioning hierarchy and easy management of module.
Consistent naming
Form and follow clear conventions for naming infrastructure resources. It helps humans to understand the context of infrastructure when needed. We use a combination of parameters to form naming. e.g. p-gojek-id-mainstream-kafka-01
Impact
Olympus allowed us to cut provisioning new infrastructure time from weeks to minutes. By breaking it down into modules, managing our infrastructure resources allowed operations and infra teams to be more efficient and organized, thus providing more business value.
This project also helped us set up the foundational organizational shift to say, “Here’s a wiki to tell you how to provision it yourself. Don’t file a ticket, don’t wait for the Infra engineering team”.